|
I graduated from the PhD programme at the Singapore University of Technology and Design (SUTD) in 2022. During my PhD journey, I was under the supervision of Prof. Gemma Roig (in Goethe University Frankfurt, Germany) and Prof. Dorien Herremans (in SUTD). |
|
My research interests include computer vision, affective computing, and multimodal representation learning. In addition to doing research, I also enjoy participating in startup projects. |
|
|

|
Thao Ha , Gemma Roig, Dorien Herremans Preprint SSRN/ Dataset/ Code We construct a collection of three datasets (called EmoMV) for affective correspondence learning between music and video modalities. A benchmark deep neural network model for binary affective music-video correspondence classification is also proposed. This proposed benchmark model is then modified to adapt to affective music-video retrieval. |
|
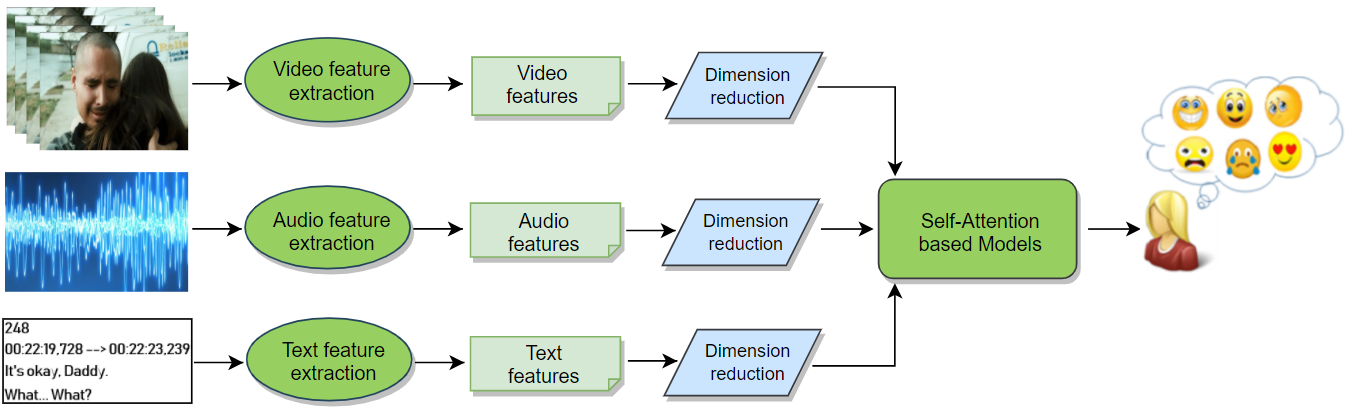
Thao Ha, Balamurali B.T, Gemma Roig, Dorien Herremans Sensors, 2021 Paper/ Code This is an extended version of the paper "AttendAffectNet: Self-Attention based Networks for Predicting Affective Responses from Movies". In addition to visual and audio features, we also use features extracted from video subtitles as the model input. Extensive experiments are also carried out. |

|
Thao Ha, Balamurali B.T, Dorien Herremans, Gemma Roig ICPR, 2020 Paper We develop a deep neural network namely AttendAffectNet for predicting emotions of movie viewers from different input modalities (video, audio) by using the self-attention mechanism. |
|
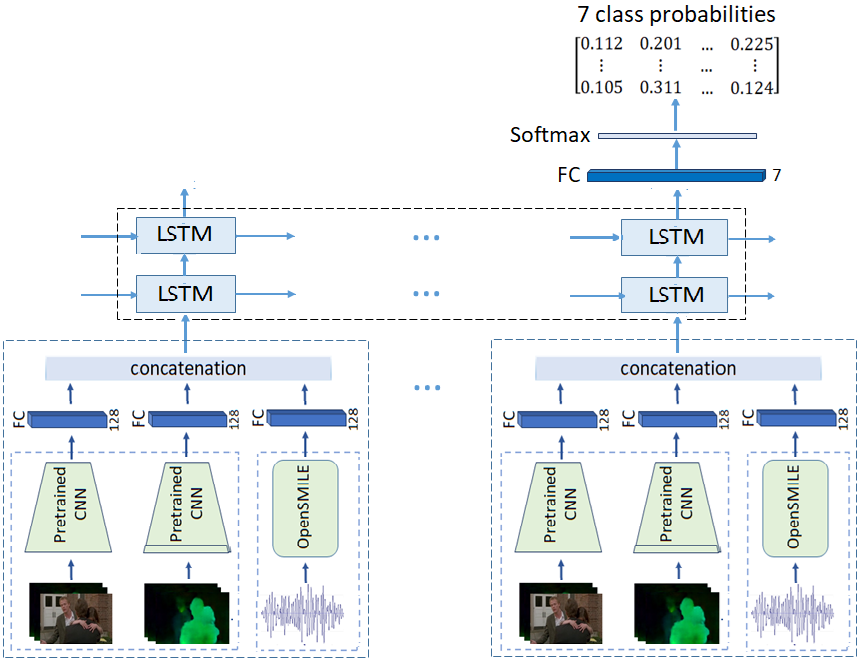
Thao Ha, Dorien Herremans, Gemma Roig CVPM, 2019 Paper / Code We develop and analyze multimodal models for predicting experienced affective responses of viewers watching movie clips. The first model is based on fully connected layers without memory on the time component, while the second one incorporates the sequential dependency with a long shortterm memory recurrent neural network (LSTM). |
|
|
|
TA, Introduction to Probability and Statistics, 2018, SUTD |
|
|
TA, Artificial Intelligence, 2019, SUTD |